
Release notes for Groovy 4.0
Groovy 4 builds upon existing features of earlier versions of Groovy. In addition, it incorporates numerous new features and streamlines various legacy aspects of the Groovy codebase.
|
Important naming/structuring changes
Maven coordinate change
In Groovy 4.0, the groupId of the maven coordinates for Groovy have changed from org.codehaus.groovy
to org.apache.groovy. Please update your Gradle/Maven/other build settings appropriately.
Legacy package removal
The Java Platform Module System (JPMS) requires that classes in distinct modules have distinct package names (known as the "split packaging requirement"). Groovy has its own "modules" that weren’t historically structured according to this requirement.
Groovy 3 provided duplicate versions of numerous classes (in old and new packages) to allow Groovy users to migrate towards the new JPMS compliant package names. See the Groovy 3 release notes for more details. Groovy 4 no longer provides the duplicate legacy classes.
In short, time to stop using groovy.util.XmlSlurper and start using groovy.xml.XmlSlurper.
Similarly, you should now be using groovy.xml.XmlParser, groovy.ant.AntBuilder, groovy.test.GroovyTestCase
and the other classes mentioned in the prior mentioned Groovy 3 release notes.
Module changes for groovy-all
Based on user feedback and download statistics, we rejigged which modules are included in the groovy-all pom
(GROOVY-9647).
The groovy-yaml module is fairly widely used and is now included in groovy-all.
The groovy-testng module is less widely used and is no longer included in groovy-all.
Please adjust your build script dependencies if needed.
If you are using the Groovy distribution, no changes are required since it
includes the optional modules.
New features
Switch expressions
Groovy has always had a very powerful switch statement, but there are times when a switch expression would be more convenient.
In switch statements, case branches with fallthrough behavior are usually much rarer
than branches which handle one case and then break out of the switch.
The break statements clutter the code as shown here.
def result
switch(i) {
case 0: result = 'zero'; break
case 1: result = 'one'; break
case 2: result = 'two'; break
default: throw new IllegalStateException('unknown number')
}A common trick is to introduce a method to wrap the switch.
In simple cases, multiple statements might reduce to a single return statement.
The break statements are gone, albeit replaced by return statements.
def stringify(int i) {
switch(i) {
case 0: return 'zero'
case 1: return 'one'
case 2: return 'two'
default: throw new IllegalStateException('unknown number')
}
}
def result = stringify(i)Switch expressions (borrowing heavily from Java) provide a nicer alternative still:
def result = switch(i) {
case 0 -> 'zero'
case 1 -> 'one'
case 2 -> 'two'
default -> throw new IllegalStateException('unknown number')
}Here, the right-hand side (following the ->) must be a single expression. If multiple statements are needed, a block can be used.
For example, the first case branch from the previous example could be re-written as:
case 0 -> { def a = 'ze'; def b = 'ro'; a + b }Switch expressions can also use the traditional : form with multiple statements
but in this case, a yield statement must be executed.
def result = switch(i) {
case 0:
def a = 'ze'
def b = 'ro'
if (true) yield a + b
else yield b + a
case 1:
yield 'one'
case 2:
yield 'two'
default:
throw new IllegalStateException('unknown number')
}The -> and : forms cannot be mixed.
All the normal Groovy case expressions are still catered for, e.g.:
class Custom {
def isCase(o) { o == -1 }
}
class Coord {
int x, y
}
def items = [10, -1, 5, null, 41, 3.5f, 38, 99, new Coord(x: 4, y: 5), 'foo']
def result = items.collect { a ->
switch(a) {
case null -> 'null'
case 5 -> 'five'
case new Custom() -> 'custom'
case 0..15 -> 'range'
case [37, 41, 43] -> 'prime'
case Float -> 'float'
case { it instanceof Number && it % 2 == 0 } -> 'even'
case Coord -> a.with { "x: $x, y: $y" }
case ~/../ -> 'two chars'
default -> 'none of the above'
}
}
assert result == ['range', 'custom', 'five', 'null', 'prime', 'float',
'even', 'two chars', 'x: 4, y: 5', 'none of the above']Switch expressions are particularly handy for cases where the visitor pattern might have been traditionally used, e.g.:
import groovy.transform.Immutable
interface Expr { }
@Immutable class IntExpr implements Expr { int i }
@Immutable class NegExpr implements Expr { Expr n }
@Immutable class AddExpr implements Expr { Expr left, right }
@Immutable class MulExpr implements Expr { Expr left, right }
int eval(Expr e) {
e.with {
switch(it) {
case IntExpr -> i
case NegExpr -> -eval(n)
case AddExpr -> eval(left) + eval(right)
case MulExpr -> eval(left) * eval(right)
default -> throw new IllegalStateException()
}
}
}
@Newify(pattern=".*Expr")
def test() {
def exprs = [
IntExpr(4),
NegExpr(IntExpr(4)),
AddExpr(IntExpr(4), MulExpr(IntExpr(3), IntExpr(2))), // 4 + (3*2)
MulExpr(IntExpr(4), AddExpr(IntExpr(3), IntExpr(2))) // 4 * (3+2)
]
assert exprs.collect { eval(it) } == [4, -4, 10, 20]
}
test()Differences to Java
-
Currently, there is no requirement that all possible values of the switch target are covered exhaustively by case branches. If no
defaultbranch is present, an implicit one returningnullis added. For this reason, in contexts wherenullis not desired, e.g. storing the result in a primitive, or constructing a non-nullableOptional, then an explicitdefaultshould be given, e.g.:// default branch avoids GroovyCastException int i = switch(s) { case 'one' -> 1 case 'two' -> 2 default -> 0 } // default branch avoids NullPointerException Optional.of(switch(i) { case 1 -> 'one' case 2 -> 'two' default -> 'buckle my shoe' })In future Groovy versions, or perhaps through tooling like CodeNarc, we expect to support the stricter checking of exhaustive case branches similar to Java. This may be implemented automatically when using Groovy’s static nature or via an additional optional type checking extension. For this reason, developers may wish to not rely on the automatic default branch returning
nulland instead provide their own default or exhaustively cover all branches.
Sealed types
Sealed classes, interfaces and traits restrict which other classes or interfaces may extend or implement them.
Groovy supports using a sealed keyword or a @Sealed annotation when writing a sealed type.
The permitted subclasses for a sealed type can be given explicitly
(using a permits clause with the sealed keyword or a permittedSubclasses annotation attribute for @Sealed), or automatically detected if compiling the relevant types
all at the same time.
For further details, see (GEP-13) and the
Groovy documentation.
As a motivating example, sealed hierarchies can be useful when specifying Algebraic or Abstract Data Types (ADTs) as shown in the following example (using the annotation syntax):
import groovy.transform.*
@Sealed interface Tree<T> {}
@Singleton final class Empty implements Tree {
String toString() { 'Empty' }
}
@Canonical final class Node<T> implements Tree<T> {
T value
Tree<T> left, right
}
Tree<Integer> tree = new Node<>(42, new Node<>(0, Empty.instance, Empty.instance), Empty.instance)
assert tree.toString() == 'Node(42, Node(0, Empty, Empty), Empty)'As another example, sealed types can be useful when creating enhanced enum-like hierarchies. Here is a weather example using the sealed keyword:
sealed abstract class Weather { }
class Rainy extends Weather { Integer rainfall }
class Sunny extends Weather { Integer temp }
class Cloudy extends Weather { Integer uvIndex }
def threeDayForecast = [
new Rainy(rainfall: 12),
new Sunny(temp: 35),
new Cloudy(uvIndex: 6)
]Differences to Java
-
The
non-sealedkeyword (or@NonSealedannotation) isn’t required to indicate that subclasses are open to extension. A future version of Codenarc may have a rule that allows Groovy developers who wish to follow that Java practice if they desire. Having said that, keeping restrictions on extension (by usingfinalorsealed) will lead to more places where future type checking can check for exhaustive use of types (e.g. switch expressions). -
Groovy uses the
@Sealedannotation to support sealed classes for JDK8+. These are known as emulated sealed classes. Such classes will be recognised as sealed by the Groovy compiler but not the Java compiler. For JDK17+, Groovy will write sealed class information into the bytecode. These are known as native sealed classes. See the@SealedOptionsannotation to have further control over whether emulated or native sealed classes are created. -
Java has requirements around classes within a sealed hierarchy being in the same module or same package. Groovy currently doesn’t enforce this requirement but may do so in a future version. In particular, it is likely native sealed classes (see previous dot point) will need this requirement.
|
|
Records and record-like classes (incubating)
Java 14 and 15 introduced records as a preview feature and for Java 16 records graduated from preview status. As per this records spotlight article, records "model plain data aggregates with less ceremony".
Groovy has features like the @Immutable and @Canonical AST transformations which already support
modeling data aggregates with less ceremony, and while these features overlap to some degree
with the design of records, they are not a direct equivalent.
Records are closest to @Immutable with a few variations added to the mix.
Groovy 4 adds support for native records for JDK16+ and also for
record-like classes (also known as emulated records) on earlier JDKs.
Record-like classes have all the features of native records but don’t have the same information at the
bytecode level as native records, and so won’t be recognised as records by a Java compiler in cross-language
integration scenarios.
See the @RecordOptions annotation for further control over whether
emulated or native records are created.
Record-like classes look somewhat similar to classes generated when using Groovy’s @Immutable AST transform.
That transform is itself a meta-annotation (also known as annotation collector)
which combines more fine-grained features. It is relatively simple to provide a record-like re-mix
of those features and that is what Groovy 4 provides with its record implementation.
You can write a record definition as follows:
record Cyclist(String firstName, String lastName) { }Or in this longer form (which is more or less what the above single-line definition is converted into):
@groovy.transform.RecordType
class Cyclist {
String firstName
String lastName
}And you’d use it as per the following example:
def richie = new Cyclist('Richie', 'Porte')This produces a class with the following characteristics:
-
it is implicitly final
-
it has a private final field
firstNamewith an accessor methodfirstName(); ditto forlastName -
it has a default
Cyclist(String, String)constructor -
it has a default
serialVersionUIDof 0L -
it has implicit
toString(),equals()andhashCode()methods
The @RecordType annotation combines the following transforms/marker annotations:
@RecordBase
@RecordOptions
@TupleConstructor(namedVariant = true, force = true, defaultsMode = DefaultsMode.AUTO)
@PropertyOptions
@KnownImmutable
@POJO
@CompileStaticThe RecordBase annotation also provides
@ToString and @EqualsAndHashCode functionality, either delegating
to those transforms or providing special native record equivalents.
We are keen for further feedback on how Groovy users might use records or record-like structures.
|
|
Built-in type checkers
Groovy’s static nature includes an extensible type-checking mechanism. This mechanism allows users to:
-
selectively weaken type checking to allow more dynamic style code to parse static checking, or
-
strengthen type checking, allowing Groovy to be much stricter than Java in scenarios where that is desirable
So far, we know this feature has been used internally by companies (e.g. type-checked DSLs),
but we haven’t seen widespread sharing of type checker extensions.
From Groovy 4, we bundle some select type checkers within the optional
groovy-typecheckers module,
to encourage further use of this feature.
The first inclusion is a checker for regular expressions. Consider the following code:
def newYearsEve = '2020-12-31'
def matcher = newYearsEve =~ /(\d{4})-(\d{1,2})-(\d{1,2}/This passes compilation but fails at runtime with a PatternSyntaxException
since we "accidentally" left off the final closing bracket.
We can get this feedback at compilation time using the new checker as follows:
import groovy.transform.TypeChecked
@TypeChecked(extensions = 'groovy.typecheckers.RegexChecker')
def whenIs2020Over() {
def newYearsEve = '2020-12-31'
def matcher = newYearsEve =~ /(\d{4})-(\d{1,2})-(\d{1,2}/
}Which gives this expected compilation error:
1 compilation error:
[Static type checking] - Bad regex: Unclosed group near index 26
(\d{4})-(\d{1,2})-(\d{1,2}
at line: 6, column: 19
As usual, Groovy’s compiler customization mechanisms would allow you to simplify application of such checkers, e.g. make it apply globally using a compiler configuration script, as just one example.
We welcome further feedback on additional type checker extensions to include within Groovy.
Built-in macro methods
Groovy macros were introduced in Groovy 2.5 to make it easier to create AST transforms and other code which manipulates the compiler AST data structures. One part of macros, known as macro methods, allows what looks like a global method call to be replaced with transformed code during compilation.
A bit like type checker extensions, we know this feature has been used in numerous places,
but so far, we haven’t seen widespread sharing of macro methods.
From Groovy 4, we bundle some select macro methods within the optional
groovy-macro-library module,
to encourage further use of this feature.
The first inclusions assist with old-school debugging (poor man’s serialization?). Suppose during coding you have defined numerous variables:
def num = 42
def list = [1 ,2, 3]
def range = 0..5
def string = 'foo'Suppose now you want to print those out for debugging purposes.
You could write some appropriate println statements and maybe sprinkle in some
calls to format(). You might even have an IDE help you do that.
Alternatively, the SV and NV` macro methods come to the rescue.
The SV macro method creates a String (actually a gapi:groovy.lang.GString)
which contains the variables name and value.
Here is an example:
println SV(num, list, range, string)which outputs:
num=42, list=[1, 2, 3], range=[0, 1, 2, 3, 4, 5], string=foo
Here, the SV macro method springs into action during the compilation process.
The compiler replaces the apparent global SV method call with an expression
which combines the names and toString() values of the supplied variables.
Two other variations exist. SVI calls Groovy’s inspect() method rather than
toString() and SVD calls Groovy’s dump() method. So this code:
println SVI(range)produces the following output:
range=0..5
And this code:
println SVD(range)yields:
range=<groovy.lang.IntRange@14 from=0 to=5 reverse=false inclusiveRight=true inclusiveLeft=true modCount=0>
The NV macro method provides similar functionality to SV but instead of
creating a "string", it creates a gapi:groovy.lang.NamedValue which lets
you further process the name and value information. Here is an example:
def r = NV(range)
assert r instanceof NamedValue
assert r.name == 'range' && r.val == 0..5There is also a NVL macro method which creates a list of NamedValue instances.
def nsl = NVL(num, string)
assert nsl*.name == ['num', 'string']
assert nsl*.val == [42, 'foo']We welcome further feedback on additional macro methods to include within Groovy. If you do enable this optional module but want to limit which macro methods are enabled, there is now a mechanism to disable individual macro methods (and extension methods) GROOVY-9675.
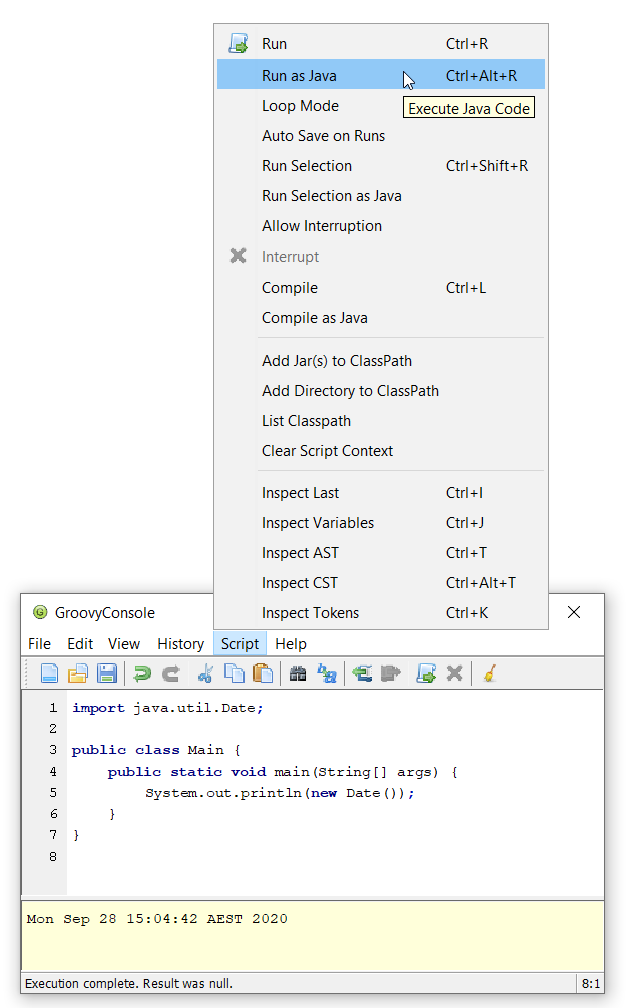
JavaShell (incubating)
A Java equivalent of GroovyShell, allowing to more easily work with snippets of Java code.
As an example, the following snippet shows compiling a record (JDK14) and checking its toString with Groovy:
import org.apache.groovy.util.JavaShell
def opts = ['--enable-preview', '--release', '14']
def src = 'record Coord(int x, int y) {}'
Class coordClass = new JavaShell().compile('Coord', opts, src)
assert coordClass.newInstance(5, 10).toString() == 'Coord[x=5, y=10]'This feature is used in numerous places within the Groovy codebase for testing purposes. Various code snippets are compiled using both Java and Groovy to ensure the compiler is behaving as intended. We also use this feature to provide a productivity enhancement for polyglot developers allowing Java code to be compiled and/or run (as Java) from within the Groovy Console:
POJO Annotation (incubating)
Groovy supports both dynamic and static natures.
Dynamic Groovy’s power and flexibility comes from making (potentially extensive) use of the runtime.
Static Groovy relies on the runtime library much less. Many method calls will have bytecode
corresponding to direct JVM method calls (similar to Java bytecode)
while the Groovy runtime is often bypassed altogether.
But even for static Groovy, hard-links to the Groovy jars remain.
All Groovy classes still implement the GroovyObject interface (and so have methods like getMetaClass and invokeMethod)
and there are some other places which call into the Groovy runtime.
The @POJO marker interface is used to indicate that the generated class is more like a plain old Java object
than an enhanced Groovy object. The annotation is currently ignored unless combined with @CompileStatic.
For such a class, the compiler won’t generate methods typically needed by Groovy, e.g. getMetaClass().
This feature is typically used for generating classes which need to be used with Java or Java frameworks
in situations where Java might become confused by Groovy’s "plumbing" methods.
The feature is incubating. Currently, the presence of the annotation should be treated like a hint to the compiler to produce bytecode not relying on the Groovy runtime if it can, but not a guarantee.
Users of @CompileStatic will know that certain dynamic
features aren’t possible when they switch to static Groovy.
They might expect that using @CompileStatic and @POJO
might result in even more restrictions.
This isn’t strictly the case.
Adding @POJO does result in more Java-like code in certain places,
but numerous Groovy features still work.
Consider the following example. First a Groovy Point class:
@CompileStatic
@POJO
@Canonical(includeNames = true)
class Point {
Integer x, y
}And now a Groovy PointList class:
@CompileStatic
@POJO
class PointList {
@Delegate
List<Point> points
}We can compile those classes using groovyc in the normal way
and should see the expected Point.class and PointList.class files produced.
We can then compile the following Java code.
We do not need the Groovy jars available for javac or java,
we only need the class files produced from the previous step.
Predicate<Point> xNeqY = p -> p.getX() != p.getY(); // (1)
Point p13 = new Point(1, 3);
List<Point> pts = List.of(p13, new Point(2, 2), new Point(3, 1));
PointList list = new PointList();
list.setPoints(pts);
System.out.println(list.size());
System.out.println(list.contains(p13));
list.forEach(System.out::println);
long count = list.stream().filter(xNeqY).collect(counting()); // (2)
System.out.println(count);-
Check whether x not equal to y
-
Count points where x neq y
Note that while our PointList class has numerous list methods available
(size, contains, forEach, stream, etc.) courtesy of Groovy’s @Delegate transform,
these are baked into the class file, and the bytecode produced doesn’t call
into any Groovy libraries or rely on any runtime code.
When run, the following output is produced:
3 true Point(x:1, y:3) Point(x:2, y:2) Point(x:3, y:1) 2
In essence, this opens up the possibility to use Groovy as a kind of pre-processor similar to Lombok but backed by the Groovy language.
|
Groovy Contracts (incubating)
This optional module supports design-by-contract style of programming. More specifically, it provides contract annotations that support the specification of class-invariants, pre-conditions, and post-conditions on Groovy classes and interfaces. Here is an example:
import groovy.contracts.*
@Invariant({ speed() >= 0 })
class Rocket {
int speed = 0
boolean started = true
@Requires({ isStarted() })
@Ensures({ old.speed < speed })
def accelerate(inc) { speed += inc }
def isStarted() { started }
def speed() { speed }
}
def r = new Rocket()
r.accelerate(5)This causes checking logic, corresponding to the contract declarations, to be injected as required in the classes methods and constructors. The checking logic will ensure that any pre-condition is satisfied before a method executes, that any post-condition holds after any method executes and that any class invariant is true before and after a method is called.
This module replaces the previously external gcontracts project which is now archived.
GINQ, a.k.a. Groovy-Integrated Query or GQuery (incubating)
GQuery supports querying collections in a SQL-like style. This could involve lists and/or maps or your own domain objects or those returned when processing for instance JSON, XML and other structured data.
from p in persons
leftjoin c in cities on p.city.name == c.name
where c.name == 'Shanghai'
select p.name, c.name as cityName
from p in persons
groupby p.gender
having p.gender == 'Male'
select p.gender, max(p.age)
from p in persons
orderby p.age in desc, p.name
select p.name
from n in numbers
where n > 0 && n <= 3
select n * 2
from n1 in nums1
innerjoin n2 in nums2 on n1 == n2
select n1 + 1, n2Let’s look at a complete example. Suppose we have information in JSON format about fruits, their prices (per 100g) and the concentration of vitamin C (per 100g). We can process the JSON as follows:
import groovy.json.JsonSlurper
def json = new JsonSlurper().parseText('''
{
"prices": [
{"name": "Kakuda plum", "price": 13},
{"name": "Camu camu", "price": 25},
{"name": "Acerola cherries", "price": 39},
{"name": "Guava", "price": 2.5},
{"name": "Kiwifruit", "price": 0.4},
{"name": "Orange", "price": 0.4}
],
"vitC": [
{"name": "Kakuda plum", "conc": 5300},
{"name": "Camu camu", "conc": 2800},
{"name": "Acerola cherries", "conc": 1677},
{"name": "Guava", "conc": 228},
{"name": "Kiwifruit", "conc": 144},
{"name": "Orange", "conc": 53}
]
}
''')Now, suppose we are on a budget and want to select the most cost-effective fruits to buy to help us achieve our daily vitamin C requirements. We join the prices and vitC information and order by most cost-effective fruit. We’ll select the top 2 in case our first choice isn’t in stock when we go shopping. We can see, for this data, Kakadu plums followed by Kiwifruit are our best choices:
assert GQ {
from p in json.prices
join c in json.vitC on c.name == p.name
orderby c.conc / p.price in desc
limit 2
select p.name
}.toList() == ['Kakuda plum', 'Kiwifruit']We can look at the same example again for XML. Our XML processing code might look something like:
import groovy.xml.XmlSlurper
def root = new XmlSlurper().parseText('''
<root>
<prices>
<price name="Kakuda plum">13</price>
<price name="Camu camu">25</price>
<price name="Acerola cherries">39</price>
<price name="Guava">2.5</price>
<price name="Kiwifruit">0.4</price>
<price name="Orange">0.4</price>
</prices>
<vitaminC>
<conc name="Kakuda plum">5300</conc>
<conc name="Camu camuum">2800</conc>
<conc name="Acerola cherries">1677</conc>
<conc name="Guava">228</conc>
<conc name="Kiwifruit">144</conc>
<conc name="Orange">53</conc>
</vitaminC>
</root>
''')Our GQuery code might look like:
assert GQ {
from p in root.prices.price
join c in root.vitaminC.conc on c.@name == p.@name
orderby c.toInteger() / p.toDouble() in desc
limit 2
select p.@name
}.toList() == ['Kakuda plum', 'Kiwifruit']In a future Groovy version we hope to provide GQuery support for SQL databases
where an optimised SQL query is generated based on the GQuery expression
much like Groovy’s DataSet functionality.
In the meantime, for small volumes of data, you can use Groovy’s standard
SQL capabilities which return queries from the database as collections.
Here is what the code would look like for a database with
Price and VitaminC tables both having name and per100g columns:
// ... create sql connection ...
def price = sql.rows('SELECT * FROM Price')
def vitC = sql.rows('SELECT * FROM VitaminC')
assert GQ {
from p in price
join c in vitC on c.name == p.name
orderby c.per100g / p.per100g in desc
limit 2
select p.name
}.toList() == ['Kakuda plum', 'Kiwifruit']
// ... close connection ...More examples could be found in the GQuery documentation (or directly in the source repo).
TOML Support (incubating)
Support is now available for handling TOML-based files including building:
def builder = new TomlBuilder()
builder.records {
car {
name 'HSV Maloo'
make 'Holden'
year 2006
country 'Australia'
homepage new URL('http://example.org')
record {
type 'speed'
description 'production pickup truck with speed of 271kph'
}
}
}and parsing:
def ts = new TomlSlurper()
def toml = ts.parseText(builder.toString())
assert 'HSV Maloo' == toml.records.car.name
assert 'Holden' == toml.records.car.make
assert 2006 == toml.records.car.year
assert 'Australia' == toml.records.car.country
assert 'http://example.org' == toml.records.car.homepage
assert 'speed' == toml.records.car.record.type
assert 'production pickup truck with speed of 271kph' == toml.records.car.record.descriptionMore examples could be found in the groovy-toml documentation.
Other improvements
GString performance improvements
GString internals were revamped to improve performance.
When safe to do so, GString toString values are now automatically cached.
While infrequently used, GStrings do permit their internal data structures to
be viewed (and even changed!). In such circumstances, caching is disabled.
If you wish to view and not change the internal data structures, you can
call a freeze() method in GStringImpl to disallow changing of the internal
data structures which allows caching to remain active.
GROOVY-9637
As an example, the following script takes about 10s to run with Groovy 3 and about 0.1s with Groovy 4:
def now = java.time.LocalDateTime.now()
def gs = "integer: ${1}, double: ${1.2d}, string: ${'x'}, class: ${Map.class}, boolean: ${true}, date: ${now}"
long b = System.currentTimeMillis()
for (int i = 0; i < 10000000; i++) {
gs.toString()
}
long e = System.currentTimeMillis()
println "${e - b}ms"Enhanced Ranges
Groovy has always supported inclusive, e.g. 3..5, and exclusive (or open on the right), e.g. 4..<10, ranges.
From Groovy 4, ranges can be closed, open on the left, e.g. 3<..5, right or both sides, e.g. 0<..<3.
The range will exclude the left or right-most values for such ranges.
GROOVY-9649
Support for decimal fraction literals without a leading zero
Groovy has previously required a leading zero for fractional values, but leaving off the leading zero is now also supported.
def half = .5
def otherHalf = 0.5 // leading zero remains supported
double third = .333d
float quarter = .25f
def fractions = [.1, .2, .3]
// can be used for ranges too (with a rare edge case you might want to avoid)
def range1 = -1.5..<.5 // okay here
def range2 = -1.5.. .5 // space is okay but harder for humans (1)
def range3 = -1.5..0.5 // leading zero edge case (1)
assert range3 == [-1.5, -.5, .5]-
A fractional value without a leading zero can’t appear immediately after the range
..operator. The three dots in a row would be confusing and similar to the varargs notation. You should leave a space (might still be confusing for humans readers) or retain the leading zero (recommended).
JSR308 improvements (incubating)
Groovy has been improving JSR-308 support over recent versions. In Groovy 4.0, additional support has been added. In particular, type annotations are now supported on generic types. This is useful for users of tools like the Jqwik property-based testing library and technologies like the Bean Validation 2 framework. Here is an example of a Jqwik test:
@Grab('net.jqwik:jqwik:1.5.5')
import net.jqwik.api.*
import net.jqwik.api.constraints.*
class PropertyBasedTests {
@Property
def uniqueInList(@ForAll @Size(5) @UniqueElements List<@IntRange(min = 0, max = 10) Integer> aList) {
assert aList.size() == aList.toSet().size()
assert aList.every{ anInt -> anInt >= 0 && anInt <= 10 }
}
}In earlier versions of Groovy, the @Forall, @Size, and @UniqueElements annotations
were handled, but the @IntRange annotation on the List generic type didn’t appear in the
generated bytecode and now does.
Here is a Bean Validation 2 framework example:
@Grab('org.hibernate.validator:hibernate-validator:7.0.1.Final')
@Grab('org.hibernate.validator:hibernate-validator-cdi:7.0.1.Final')
@Grab('org.glassfish:jakarta.el:4.0.0')
import jakarta.validation.constraints.*
import jakarta.validation.*
import groovy.transform.*
@Canonical
class Car {
@NotNull @Size(min = 2, max = 14) String make
@Min(1L) int seats
List<@NotBlank String> owners
}
def validator = Validation.buildDefaultValidatorFactory().validator
def violations = validator.validate(new Car(make: 'T', seats: 1))
assert violations*.message == ['size must be between 2 and 14']
violations = validator.validate(new Car(make: 'Tesla', owners: ['']))
assert violations*.message.toSet() == ['must be greater than or equal to 1', 'must not be blank'] as Set
violations = validator.validate(new Car(make: 'Tesla', owners: ['Elon'], seats: 2))
assert !violationsAgain, all annotations except the @NonBlank annotation on the List generic type
were previously supported, and now @NonBlank will appear in the bytecode too.
This feature is marked as incubating. The generated bytecode is not expected to change but some minor details of the AST representation of the annotations during compilation may change slightly before the feature leaves incubating status.
In addition, type annotations that appear in code, e.g. local variable types, cast expression types, catch block exception types, are still work in progress.
AST transformation priorities
The order in which AST transforms are processed is determined first by the phase
declared in a transform’s @GroovyASTTransformation declaration.
For transforms declared to be in the same phase, the order in which the
associated transform annotations appear in the source code is then used.
Now, transformation writers can also specify a priority for their transforms.
To do so, the AST transformation must implement the TransformWithPriority interface
and return their priority as an integer in the implemented priority() method.
The default priority is 0. The transformation with the highest positive priority
will be processed first. Negative priorities will be processed after all transformations
with a priority of zero (the default).
Note that transformations are still all processed together. The priority only affects ordering between other transformations. Other parts of the respective compiler phase remain unchanged.
Legacy consolidation
Old parser removal
Groovy 3 introduced the new "Parrot" parser which supports lambdas, method references, and numerous other tweaks. In Groovy 3, You could still revert to the old parser if you wanted. In Groovy 4, the old Antlr2 based parser is removed. Please use older versions of Groovy if you require the old parser.
Invokedynamic bytecode enabled by default
For many versions, Groovy could generate classic call-site based bytecode
or bytecode targeting the JDK7+ invoke dynamic ("indy") bytecode instructions.
You could switch between them with a compiler switch and we had two sets of
jars ("normal" and "-indy") built with and without the switch enabled.
In Groovy 4.0, invokedynamic bytecode generation is enabled by default.
There is now one set of jars and they are compiled with indy enabled.
It is still possible to disable invokedynamic for user code by setting the
system property groovy.target.indy to false or by setting the
indy compiler optimization option to false.
Currently, the Groovy runtime still contains any necessary support for classes compiled using older versions of Groovy.
This work was originally planned for Groovy 3.0, but there were numerous places
where "indy" code was noticeably slower than "classic" bytecode.
We have made numerous speed improvements (starting with GROOVY-8298)
and have some ability to tune internal thresholds (search the code base for
groovy.indy.optimize.threshold and groovy.indy.fallback.threshold).
That work gave us useful speed improvements, but we welcome further feedback
to help improve overall performance of the indy bytecode.
Other breaking changes
-
Groovy added some very minor enhancements when using the JAXB technology in its optional
groovy-jaxbmodule. Since JAXB is no longer bundled in the JDK, we removed this module. Users wanting that functionality are likely able to use the Groovy 3 version of that module with Groovy 4, though we don’t guarantee this going forward. (GROOVY-10005). -
The optional
groovy-bsfmodule provides a Groovy BSF engine for the version 2 of BSF (a.k.a. beanshell) framework. This version hasn’t had a release since 2005 and has reached end-of-life. In Groovy 4 we have removed this module. Users wanting that functionality are likely able to use the Groovy 3 version of that module with Groovy 4, though we don’t guarantee this going forward. (GROOVY-10023). -
Numerous classes previously "leaked" ASM constants which are essentially an internal implementation detail by virtue of implementing an
Opcodesinterface. This will not normally affect the majority of Groovy scripts but might impact code which manipulates AST nodes such as AST transforms. Before compiling with Groovy 4, some of these may need one or more appropriate static import statements added. AST transforms which extendAbstractASTTransformationare one example of potentially affected classes. (GROOVY-9736). -
ASTTestpreviously hadRUNTIMEretention but now hasSOURCEretention. We know of no users making use of the old retention but are aware of various issues keeping the old value. GROOVY-9702 -
Groovy’s
intersectDGM method had a different semantics to other languages when supplied with a projecting closure/comparator. Other languages often have aintersectBymethod in this case rather than overloading theintersectoperator like Groovy does. When no projecting function is in play,a.intersect(b)should always equalb.intersect(a). When a projecting function is in play, most languages definea.intersect(b)as the subset of elements fromawhich when projected match a projected value fromb. So the resulting values are always drawn froma. The objects involved can be reversed to draw the elements fromb. Groovy’s semantics used to be the reverse of most other languages but is now aligned. Some examples with the new behavior:def abs = { a, b -> a.abs() <=> b.abs() } assert [1, 2].intersect([-2, -3], abs) == [2] assert [-2, -3].intersect([1, 2], abs) == [-2] def round = { a, b -> a.round() <=> b.round() } assert [1.1, 2.2].intersect([2.5, 3.5], round) == [2.2] assert [2.5, 3.5].intersect([1.1, 2.2], round) == [2.5]Simply reverse the order of the objects to get the previous behavior, e.g. use
foo.intersect(bar)instead ofbar.intersect(foo). GROOVY-10275 -
There were some inconsistencies with JavaBean property naming conventions for various edge cases, e.g. for a field with a name being a single uppercase
Xand having agetXaccessor, then the field was given priority over the accessor. GROOVY-9618 -
Numerous mostly internal data structure classes, e.g. AbstractConcurrentMapBase, AbstractConcurrentMap, ManagedConcurrentMap were deprecated and their usage replaced with better alternatives. This should be mostly invisible but some changes might impact users using internal Groovy classes directly. GROOVY-9631
-
We bumped our Picocli version. This resulted in minor formatting changes of some CLI help messages. We recommend not relying on the exact format of such messages. GROOVY-9627
-
We are currently attempting to improve how Groovy code accesses private fields in certain scenarios where such access is expected but problematic, e.g. within closure definitions where subclasses or inner classes are involved (GROOVY-5438). You may notice breakages in Groovy 4 code in such scenarios until this issue is progressed. As a workaround in the meantime, you may be able to use local variable outside a closure to reference the relevant fields and then reference those local variables in the closure.
-
Earlier Groovy versions unintentionally stored the constants -0.0f and -0.0d to be the same as 0.0f and 0.0d respectively. This only applied to explicit constants, i.e. it didn’t apply to calculations which resulted in positive or negative zero. This also meant that certain comparisons of positive and negative zero returned true in cases where they should have been different, and calling
uniquemight have resulted in a set containing just positive zero instead of both positive and negative zero (the correct answer as per IEEE-745). Depending on whether you are using primitive or wrapper floating point variants, you may or may not be affected. Consider usingequalsIgnoreZeroSignand the booleanignoreZeroSignconstructor variant toNumberAwareComparatorif you are affected and desire the old behavior. These modifications have also been back-ported to Groovy 3, so consider using them in Groovy 3 code instead of relying on the old behavior so that your code can work correctly across versions. The fix itself hasn’t been back-ported to avoid breaking existing code relying on the unintended flawed behavior.
Bug fix: GROOVY-9797
Improved documentation and helper methods: GROOVY-9981 -
Various Groovy test classes had unnecessary hidden dependencies on JUnit 3/4 classes. After modification, these classes can now be used with e.g. JUnit 5 (or Spock) without Junit 3/4 on the classpath. It is a breaking change only if code is looking explicitly at the class of thrown exceptions or inspecting the class hierarchy through reflection.
NotYetImplemented: GROOVY-9492
GroovyAssert: GROOVY-9767 -
Several
Sql#callvariants incorrectly throwExceptionrather thanSQLException. This is a binary breaking change. Care should be taken with compiling code relying on those methods with an older version of Groovy and then running on Groovy 4 and vice versa. GROOVY-9923 -
We removed
StaticTypeCheckingVisitor#collectAllInterfacesByNamefrom our public API as it was buggy and there were numerous alternatives available. We weren’t aware of any framework use of this method. Even though it was public, it was considered mostly internal. GROOVY-10123 -
Two jar files (
servlet-api.jarandjsp-api.jar) were notionally "provided" dependencies but were previously copied into the Groovy binary distribution. This is no longer the case. GROOVY-9827 -
Groovy code involving
pluson arrays broke referential transparency in certain contexts. The expressionb + c, wherebandcare arrays, potentially gave different results in the two expressionsa = b + candb = b + c. The latter of these expressions (shorthand forb += c) was type preserving but the former was returned as an Object[]. The type preserving behavior was the intended one. GROOVY-6837.TipTo mimic the old behavior: If
bis not an Object array and you desire an Object array result, then instead ofb + c, use one of:-
b.union(c) -
new Object[0] + b + c -
[] as Object[] + b + c
-
-
Groovy’s syntax borrows an "information hiding principal" idea from the Eiffel programming language whereby accessing a public field or a property (private field with a getter) can have the same syntactic form. This idea wasn’t carried over to the
getProperties()method in an object’s metaclass. NowgetProperties()also returns public fields. GROOVY-10449. -
The code for generating needed calls to make Groovy’s Meta-Object-Protocol (MOP) work correctly with runtime selection of super calls was created back in Groovy 1.0 days and didn’t account for things like default methods in interfaces. Attempts to patch this over time have left a number of inconsistencies and faulty edge cases. MOP method generation and method indexing were changed in Groovy 4 to use a more sophisticated approach that doesn’t have the limitations of the earlier design, but unfortunately full backwards compatibility was not possible. This isn’t a concern when compiling a complete set of Groovy source files, but can cause problems when compiling Groovy source files under Groovy 4+ with libraries built by pre-Groovy 4 versions or vice versa. A workaround is to use
@CompileStaticfor impacted super calls which alleviates the problem. GROOVY-8693. -
Groovy 4 attempts to align
Booleanproperty access more closely with JavaBean conventions. The JavaBeans specification indicates that for a primitivebooleanpropertyfoo, the accessor method can be eitherisFoo()orgetFoo(). The JavaBean specification doesn’t indicate that the "is" variant is applicable toBooleanproperties. In earlier Groovy versions, sometimesisFoo()was allowed forBooleanproperties, and not allowed in other cases. Also, in some places Groovy generated bothisFoo()andgetFoo()accessors for such properties which caused problems for introspection-based frameworks and (de)serialization libraries, sometimes causing a property to be included twice. Groovy 4 sticks more closely to the JavaBean specification, so the recommendation is that users wanting to useisFoo(), should use primitivebooleanproperties. Users dealing with introspection-based frameworks and (de)serialization libraries can useBooleanproperties (and agetFoo()accessors if needed) to be sure they won’t have duplication issues. Metaprogramming can also be used to reintroduce the old behavior in numerous cases if needed. GROOVY-8392, GROOVY-10133.
JDK requirements
Groovy 4.0 requires JDK16+ to build and JDK8 is the minimum version of the JRE that we support. Groovy has been tested on JDK versions 8 through 17.
More information
You can browse all the tickets closed for Groovy 4.0 in JIRA.
Addendum for 4.0.2
-
Groovy 4 enhanced the metadata stored for its dependencies using Gradle’s module metadata feature. As part of this change, accessing the
groovy-alldependency changed in a way that was confusing for many users. In particular, there was a requirement to useplatformthat was not required before. The module metadata has been improved and usingplatformis no longer required. GROOVY-10543 -
Preliminary JDK19 support has been added
-
Groovy optionally supports the use of security policy files to trigger security exceptions if unpermitted operations are performed (e.g. reading properties, exiting the JVM or accessing resources like files). With the Java plan to phase out security policy framework (JEP-411), future Groovy versions will likely phase out this optional support. In the meantime, users could expect warning messages if using such features and potentially exceptions in JDK 18 or 19.
-
Of particular note around security exceptions (see previous point), when using
groovyshon JDK18 or JDK19, users should setJAVA_OPTSto-Djava.security.manager=allow. Thegroovyshtool uses a security manager to prohibit calls toSystem::exit. Alternative APIs to deal with this scenario are expected to emerge at some point andgroovyshwill move to those when available.
Addendum for 4.0.33
-
Groovy 4.0.33 bumped the ASM version so that it now will read classes created on later JDK versions: JDK26 and 27. Less extensive testing has occurred for Groovy 4 on these JDK versions and in particular, the Groovy Console is known not to work on JDK26+. Switch to Groovy 5/6 or use JDK versions up to 25 if using the Groovy Console in Groovy 4.